 N O T I C E
N O T I C E
MSPbots WIKI is moving to a new home at support.mspbots.ai![]() to give you the best experience in browsing our Knowledge Base resources and addressing your concerns. Click here
to give you the best experience in browsing our Knowledge Base resources and addressing your concerns. Click here![]() for more info!
for more info!
Page History
...
| Setting | Default | Description |
|---|---|---|
| Model | - | The Model setting is to select the OpenAI model you want to use. The options for the Model from the available models in your OpenAI integration, including GPT-4. If you haven't connected OpenAI integration to MSPbots yet or if MSPbots is unable to fetch the available GPT models from your OpenAI integration, the option will be empty. If you want to know how to connect OpenAI integration, please refer to OpenAI Integration Setup. If you have previously configured the Open AI bot block's model as GPT-3.5-turbo, then the model will still be GPT-3.5-turbo. |
| Temperature | 0.2 | The Temperature setting is common to all ChatGPT functions and is used to fine-tune the sampling temperature by a number between 0 and 1. Use 1 for creative applications and 0 for well-defined answers. Example: If you would like to return factual or straightforward answers such as a country's capital, then use 0. For tasks that are not as straightforward such as generating text or content, a higher temperature is required to enable the capture of idiomatic expressions and text nuances. |
| Max Length | 120 | Max Length represents the maximum number of tokens used to generate prompt results. Tokens can be likened to pieces of words that the model uses to classify text. 1 token ~= 4 characters |
| Top P | 0.2 | Top-p sampling, also known as nucleus sampling, is an alternative to temperature sampling. Instead of considering all possible tokens, GPT-3 considers only a subset or a nucleus whose cumulative probability mass adds up to a threshold which is set as the top-p. If the Top P is set to 0.2, GPT-3 will only consider the tokens that make up the top 20% of the probability mass for the next token, allowing for dynamic vocabulary selection based on context. |
| Frequency Penalty | 0 | Frequency Penalty is mostly applicable to text generation. This setting tells the model to limit repeating tokens like a friendly reminder to not overuse certain words or phrases. Since this is mostly not applicable to sentiment analysis, it is set to 0. |
| Presence Penalty | 0 | The Presence Penalty parameter tells the model to include a wider variety of tokens in generated text and, like the frequency penalty, is applicable to text generation as compared to sentiment. |
...
The screenshot of the OpenAI bot block window below shows these settings.

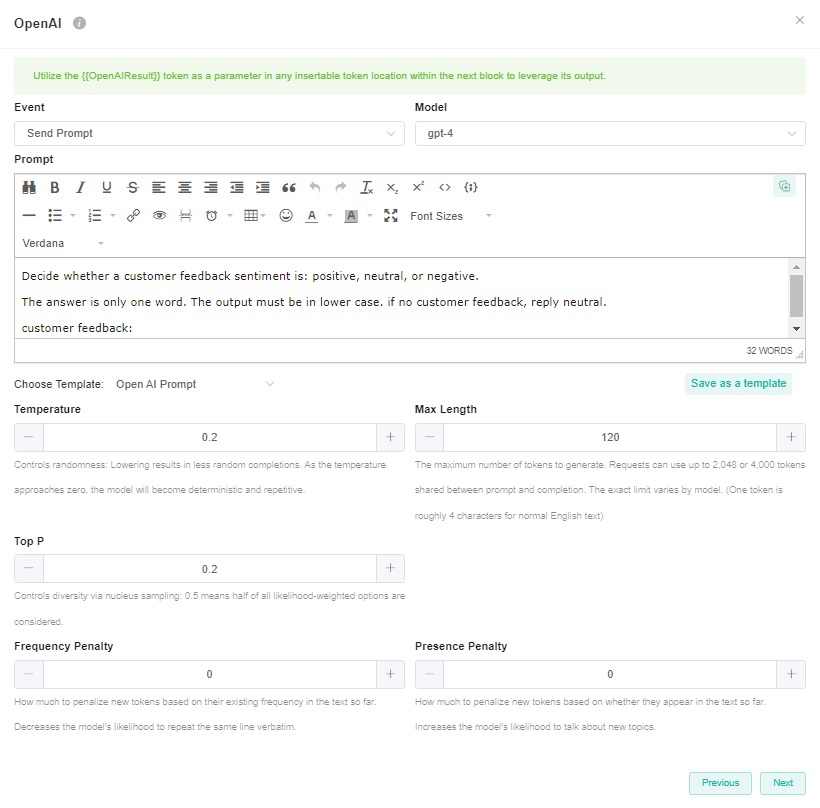
You are ready to activate the OpenAI Sentiment Analysis Bot after the additional filters and settings are applied.
...
Overview
Content Tools